1
定论
CPU概述
- CPU的功能和基本概述
- CPU的基本结构
- 运算器 - 对数据进行算术运算、逻辑运算或条件测试。主要包括算术逻辑单元ALU、暂存寄存器、累加寄存器ACC、通用寄存器组GPRs、程序状态字寄存器PSW、移位寄存器、计数器CT等
- 控制器 - 通过微操作执行指令。主要包括程序计数器PC、指令寄存器IR、指令译码器ID、存储器地址寄存器MAR、存储器数据寄存器MDR、时序电路和微操作信号发生器等
- CPU的寄存器
- 用户可见寄存器 - 通用寄存器组、程序状态字寄存器、程序计数器、累加寄存器、移位寄存器等
- 用户不可见寄存器(透明) - 存储器地址寄存器、存储器数据寄存器、指令寄存器、暂存寄存器
- 几个重要的寄存器作用
- 程序计数器PC - 存放欲执行指令再主存中位置,位数和主存地址位数相同
- 指令寄存器IR - 存放当前正在执行的指令,位数等于指令字长
指令执行流程
指令周期的定义,以及指令周期由多个机器周期组成
若CPU采用终端形式实现主机和I/O的信息交换,那么指令周期会多出一个变为四个周期 - 取址周期、间址周期、执行周期、中断周期
取址周期PC+“1”,中断周期SP-“1”
指令周期的数据琉



执行周期不同的指令数据流不同
数据通路的基本结构
- CPU内部单总线方式
- 定义 - ALU及所有寄存器连接到一条内部公共总线上
- 图示

- 能输出到总线的部件均与一个三态门连接,用于控制该部件与内部总线之间数据通路的连接与断开
- 豆指导总结的表格 ```markdown | 操作类型 | 数据流程 | 关键控制信号 | 典型场景及说明 | |——————|————————————————————————–|—————————————————————————-|——————————————————————————| | 寄存器间传输 | (R1) → 总线 → R2 | RegRead=1, R1_sel=1, RegWrite=1, R2_addr, CLK | 将寄存器R1的值复制到R2,如MOV指令实现 | | 存储器读 | (PC) → MAR → 存储器 → MDR → 总线 → R1 | PC_out=1, MAR_in=1, MemRead=1, MDR_in=1, MDR_out=1, RegWrite=1, R1_addr | 从内存加载数据到寄存器,如LOAD指令 | | 存储器写 | (PC) → MAR; (R1) → MDR → 存储器[MAR] | PC_out=1, MAR_in=1, RegRead=1, R1_sel=1, MDR_in=1, MemWrite=1, MDR_out=1 | 将寄存器数据写入内存,如STORE指令 | | ALU运算 | (R1) → ALU_A; (R2) → ALU_B → ALU → ALU_Out → 总线 → R3 | RegRead=1, R1_sel=1, R2_sel=1, ALU_A_in=1, ALU_B_in=1, ALU_Op=001(加法), ALU_Out=1, RegWrite=1, R3_addr | 执行算术/逻辑运算,如ADD/SUB指令 | | PC更新 | (PC) + 4 → PC | PC_out=1, ALU_A_in=1, ALU_B_in=1(设为4), ALU_Op=010(加法), PC_in=1 | 取指后PC自增,指向下一条指令 | | 条件分支(BEQ) | (R1-R2)→ALU_Out→ZF; (PC+Offset)→ALU_Out; if(ZF) then (ALU_Out) → PC | RegRead=1, R1_sel=1, R2_sel=1, ALU_Op=100(减法), PC_out=1, ALU_B_in=1(Offset), ALU_Op=010(加法), Branch=1, ZF=1, PC_in=1 | 相等时跳转,如BEQ指令 |
控制器的功能和工作原理
- 控制器的结构与功能
- 硬布线控制器的图示与功能
- 微程序控制器
- 基本概念 - 每条机器指令编写成微程序,每个微程序包含若干微指令,每条微指令对应一个或几个微操作命令
- 控制存储器CM用于存放微程序,因此在CPU内部,用控制存储器来存放微程序,用ROM实现
- 微程序的结构和功能是是透明的
- 微程序控制器的组成
- 微指令编码方式
- 直接编码方式 - 无需译码,操作控制字段的每一位都表示一个微命令
- 字段直接编码方式 - 互斥性微命令放在同一字段、向同性微命令放在不同字段
- 字段间接编码方式 - 一个字段某些微命令需另一个字段的某些微命令来解释
- 微指令格式
- 水平型微指令
- 核心特点:并行控制,微指令字长较长(100-200位),每个控制位直接对应硬件信号。
- 优势:无需译码,并行执行效率高,灵活性强,适合复杂微操作组合。
- 劣势:字长过长,占用ROM空间大,硬件成本高。
- 适用场景:高性能CPU(如超标量、流水线处理器)。
- 垂直型微指令
核心特点:串行控制,微指令字短(20-50位),通过微操作码译码生成控制信号。
优势:节省ROM空间,硬件成本低,易于扩展新微操作。
劣势:需多次译码,执行速度慢,微操作组合受限于 opcode设计。
适用场景:微控制器、低成本嵌入式系统。
维度 水平型 垂直型 控制方式 并行直接控制 串行译码控制 字长 长 短 执行效率 高 低 空间效率 低 高
- 微指令的地址形成方式
- 后继地址字段指出
- 机器指令操作码指出
- 增量计数器法
- 各个标志决定下一条微指令分支转移的地址
- 硬件直接产生微程序入口地址
- 对比两种控制器

异常和中断机制
- 异常和中断的基本概念
- 异常的分类 - 故障、自陷
- 中断的分类 - 可屏蔽中断和不可屏蔽中断、
- 所有异常和中断事件都是由硬件检测发现的
- 异常和中断响应过程
- 关中断
- 保存断点和程序状态
- 识别异常和中断并转到相应的处理程序
- 硬件识别方式(向量中断) - 所有中断向量放在一个中断向量表中
- 软件识别方式 - CPU设计一个异常状态寄存器,操作系统使用统一的异常或中断程序、按优先级查询异常状态寄存器
指令流水线
- 两种技术
- 时间上并行 - 一个任务分为几个不同的子阶段,每个子阶段在不同的功能部件上执行
- 空间上并行 - 一个处理机内设置多个执行相同任务的功能部件、这样的处理机被叫做超标量处理机
- 指令流水线图示
五个基本功能段 - 取址IF、译码/读寄存器ID、执行/计算地址EX、访存MEM、写回WB - 流水线的设计 - 只能用执行最慢的指令作为设计时钟周期的依据
- 流水线的几种冒险
- 结构冒险
- 不同指令在同一时刻争用同一部件
- 解决方法一 - 前一指令访存时、使后一条指令及其后续指令暂停一个时钟周期
- 解决方法二 - 设置多个独立部件,如寄存器读口和写口分离
- 数据冒险
- 后面指令要用到前面指令的结果,但是前面指令结果还未产生
- 解决方法一 - 相关指令及后续指令都暂停一至几个时钟周期。可分为软件插入空操作nop和硬件阻塞stall两种方法
- 解决方法二 - 转发(旁路)技术。数据通路形成的中间数据直接送到ALU的输出端
- 特殊案例 - load-use数据冒险处理,不能转发,z只能插入nop指令,或是在编译的时候优化
- 控制冒险 - 遇到转移指令或是返回指令;发生异常或中断时改变了PC的值。解决方法是插入nop或阻塞,或者对转移指令进行分支预测
- 结构冒险
- 流水线的性能指标
- 吞吐率(Throughput, TP)
定义:单位时间内流水线完成的指令数,反映流水线的“处理速度”。
- 吞吐率(Throughput, TP)
(1)理想情况(无阻塞,流水线满负荷)
- 公式:
$$ TP_{\text{理想}} = \frac{1}{\Delta t}
$$
其中,Δt
为流水线时钟周期(每个流水段的延迟,取各段中最长延迟)。
- 含义:当流水线连续流动(第1条指令进入后,每Δt完成1条指令),吞吐率达到最大值,即每个时钟周期完成1条指令。
(2)实际情况(n条指令,k段流水线,无阻塞)
- 公式:
$$ TP_{\text{实际(无阻塞)}} =
\frac{n}{T_{\text{总}}} = \frac{n}{(k + n - 1) \cdot \Delta t}
$$
其中:
- n 为指令总数;
- k 为流水线段数;
- T总
为完成n条指令的总时间(第1条指令需k ⋅ Δt,后续n-1条各需Δt,总时间为k ⋅ Δt + (n − 1) ⋅ Δt)。
当 n ≫ k(指令数远大于段数):
$$ TP_{\text{实际(无阻塞)}} \approx \frac{n}{n \cdot \Delta t} = \frac{1}{\Delta t} = TP_{\text{理想}} $$
即接近理想吞吐率。若总阻塞周期为 b(因冒险插入的气泡总时间),则总时间 T总 = (k + n − 1 + b) ⋅ Δt,公式:
$$ TP_{\text{实际(有阻塞)}} = \frac{n}{(k + n - 1 + b) \cdot \Delta t} $$阻塞会降低吞吐率,b 越大,TP 越小。
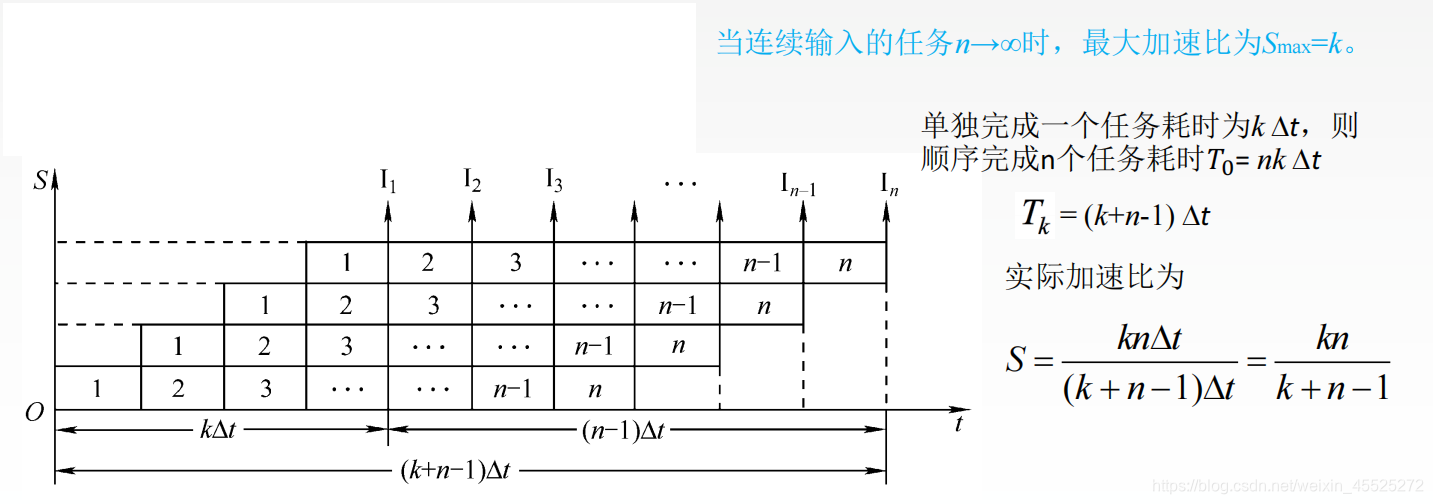
- 加速比(Speedup, S)
定义:流水线方式与非流水线方式完成相同指令集的时间比,反映流水线的“提速效果”。
- 加速比(Speedup, S)
(1)理想情况(无阻塞)
- 非流水线时间:T非流水 = n ⋅ k ⋅ Δt(每条指令需k个周期,无并行)。
- 流水线时间:T流水 = (k + n − 1) ⋅ Δt。
- 公式:
$$ S_{\text{理想}} =
\frac{T_{\text{非流水}}}{T_{\text{流水}}} = \frac{n \cdot k \cdot \Delta
t}{(k + n - 1) \cdot \Delta t} = \frac{n \cdot k}{k + n - 1}
$$
- 当 n ≫ k
时:
$$ S_{\text{理想}} \approx \frac{n \cdot k}{n} = k $$
即最大加速比接近流水线段数k(理论上限)。
(2)实际情况(有阻塞)
- 若总阻塞周期为b,则流水线时间 T流水 = (k + n − 1 + b) ⋅ Δt,公式:
$$ S_{\text{实际}} = \frac{n \cdot k \cdot
\Delta t}{(k + n - 1 + b) \cdot \Delta t} = \frac{n \cdot k}{k + n - 1 +
b} $$
- 阻塞会降低加速比,b 越大,S 越小(例如:若b = n,则$S \approx \frac{k}{2}$,加速比减半)。
3. 效率(Efficiency, E)
定义:流水线中各段的平均利用率,反映“资源利用程度”。
(1)理想情况(无阻塞)
- 总有效工作时间:n ⋅ Δt(每条指令在1个周期内占用1个段,n条指令累计有效时间)。
- 总时间×总段数:T流水 ⋅ k = (k + n − 1) ⋅ Δt ⋅ k(所有段的总“可工作时间”)。
- 公式:
$$ E_{\text{理想}} =
\frac{\text{总有效工作时间}}{\text{总时间} \times \text{总段数}} =
\frac{n \cdot \Delta t}{(k + n - 1) \cdot \Delta t \cdot k} = \frac{n}{k
\cdot (k + n - 1)} $$
- 当 n ≫ k
时:
$$ E_{\text{理想}} \approx \frac{n}{k \cdot n} = \frac{1}{k} $$
即效率接近1/k(各段平均利用率为1/k,因同一时间只有1个段在工作,其余空闲)。
(2)实际情况(有阻塞)
- 总有效工作时间不变(仍为n ⋅ Δt),总时间因阻塞增加为(k + n − 1 + b) ⋅ Δt,公式:
$$ E_{\text{实际}} = \frac{n}{k \cdot (k + n
- 1 + b)} $$
- 阻塞会降低效率(空闲时间增加,资源利用率更低)。
总结:核心公式表
| 指标 | 理想情况(无阻塞,n→∞) | 实际情况(n条指令,k段,阻塞周期b)
|
|————|————————–|——————————————-|
| 吞吐率 | TP = 1/Δt
| TP = n/[(k + n − 1 + b) ⋅ Δt]
|
| 加速比 | S = k |
S = (n ⋅ k)/(k + n − 1 + b)
|
| 效率 | E = 1/k |
E = n/[k ⋅ (k + n − 1 + b)]
|
- 高级流水线技术
- 超标量流水线技术 - 也叫动态多发射技术。每个时钟周期并发执行多条独立指令。结合动态流水线调度技术乱序执行
- 超长指令字技术 - 也叫静态多发设备技术。多条能并行操作的指令组合成一条具有多个操作码的超长指令字
- 超流水线技术 - 提高主频的方式。但是CPI还是为1.其余两种CPI都大于1
多处理器基本概念
- SISD单指令单数据流
- SIMD单指令多数据流 - 使用for循环处理数组时最容易
- MISD多指令单数据流 - 不存在
- MIMD多指令多数据流
- 超线程技术
- 硬件多线程基本概念
- 多核处理器基本概念
- 共享多处理器基本概念